98.7% Retrieval Accuracy from Metadata You Already Have
Fine-tuning embedding models for aviation NOTAM retrieval — and why bigger models aren't always better out of the box.
NOTAM processing systems have always struggled with embedded free-text fields. Even post-AIXM 5.2, free-text comments still contain meaning — and Large Language Models (LLMs) almost certainly have a role to play in understanding the impact or relevance of a NOTAM to operations. This is on top of the deterministic filtering possible with explicit codes and validation rules. Brittle heuristics and regex patterns simply cannot cover all the edge cases when humans are typing into a box on an electronic form.
This experiment took a stab at fine-tuning embedding models to see how their performance and accuracy could be improved. Can we help them understand our esoteric codes a little better? Read on to find out — and why bigger models aren't always better out of the box.
Ask a general-purpose embedding model to find NOTAMs about VOR outages, and it'll confidently return airspace reservations, ILS calibration notices, and airway descriptions. It understands English just fine. It just doesn't understand aviation.
We set out to fix that — and discovered that the labels we needed for training were hiding in the data all along.
The Retrieval Problem
NOTAMs (Notices to Air Missions) are short, dense messages that communicate critical aviation information — runway closures, navigation aid outages, airspace restrictions, obstacle erections:
RWY 04L/22R CLSD DUE TO MAINT
TWY B LGT SYS INOP
ILS RWY28 ON TEST. DO NOT USE, FALSE GLIDEPATH INDICATIONS POSSIBLE
MOBILE CRANE WITHIN 181FT RADIUS CENTRE PSN 492023N 0970345W
When you build a retrieval-augmented generation (RAG) pipeline over these — "Is it safe to land on runway 04L?" — the retrieval step matters enormously. A model that doesn't know "RWY CLSD" and "TWY LGT INOP" are fundamentally different safety concerns, or that "VOR U/S" and "NDB U/S" are semantically similar (both navigation aid outages), will return dangerously irrelevant results.
At Airside Labs, we build AI compliance and testing tools for safety-critical aviation systems. Getting retrieval right isn't an academic exercise — it directly affects whether an AI system gives a pilot or dispatcher trustworthy information.
The Insight: Q-Codes as Free Supervision
Every NOTAM carries a Q-code — a 5-character ICAO classification encoding what the NOTAM is about. The structure is Q + 2-character feature + 2-character condition:
| Q-code | Feature | Condition | Meaning |
|---|---|---|---|
QMRLC |
MR (runway) |
LC (closed) |
Runway closed |
QMRAS |
MR (runway) |
AS (unserviceable) |
Runway unserviceable |
QNVAS |
NV (VOR) |
AS (unserviceable) |
VOR out of service |
QOBCE |
OB (obstacle) |
CE (erected) |
New obstacle erected |
QFALT |
FA (aerodrome) |
LT (limited) |
Aerodrome facilities limited |
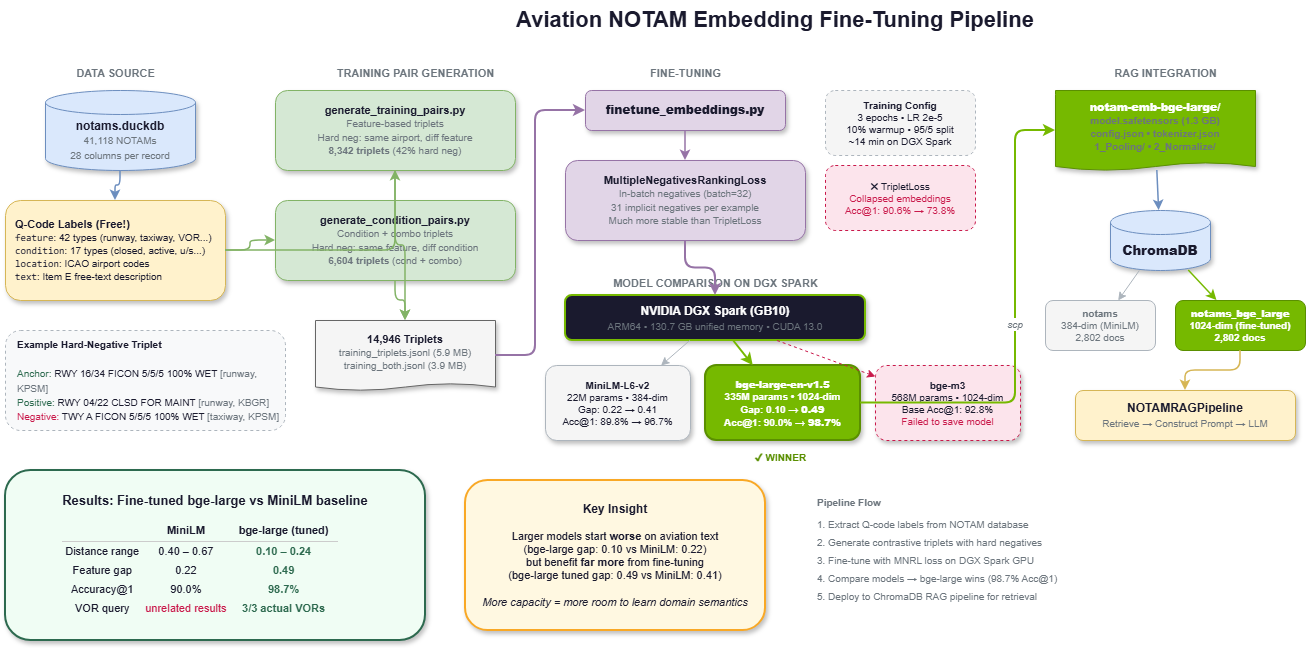
These codes are already parsed and stored in our NOTAM database. That gives us 41,118 labelled NOTAMs across 42 feature types and 17 condition types — for free. No manual annotation needed.
Generating Contrastive Training Pairs
We built two complementary training pair generators to create (anchor, positive, negative) triplets from the Q-code taxonomy.
Feature-based triplets group NOTAMs by their feature code. The anchor is a NOTAM's free-text description, the positive is another NOTAM with the same feature type, and the negative is a different feature type. The key design choice is hard negatives: instead of picking a random negative, we pick a NOTAM from the same airport but a different feature type. This forces the model to learn that "runway closed at KJFK" and "taxiway lighting out at KJFK" are semantically different, even though they share location context.
Anchor: "RWY 16/34 FICON 5/5/5 100 PCT WET" [runway, KPSM]
Positive: "RWY 04/22 CLSD FOR MAINT" [runway, KBGR]
Negative: "TWY A FICON 5/5/5 100 PCT WET" [taxiway, KPSM]
That negative is deliberately hard — same airport, same surface condition report format, but about a taxiway, not a runway. A model that gets this right truly understands aviation categories.
Condition-based and combo triplets add finer discrimination: same condition = positive, different condition = negative, with hard negatives using the same feature but different condition (e.g., "runway closed" vs "runway activated").
Combined: 14,946 training triplets, with 42.3% hard negatives across the feature-based set.
The Loss Function Matters More Than You Think
Our first attempt used TripletLoss from sentence-transformers — the obvious choice for triplet training data. It collapsed the embedding space:
| Metric | Before Training | After TripletLoss |
|---|---|---|
| Feature gap | 0.21 | 0.15 |
| Accuracy@1 | 91.5% | 73.8% |
The model got worse. TripletLoss with a fixed margin is notoriously unstable — it can push all embeddings into a small region where everything looks similar.
The fix was switching to MultipleNegativesRankingLoss (MNRL), which uses in-batch negatives. Instead of explicit triplets, you feed it (anchor, positive) pairs, and every other positive in the batch serves as a negative. With batch size 64, that's 63 implicit negatives per example — far more training signal per step.
train_examples = [
InputExample(texts=[t["anchor"], t["positive"]])
for t in train_triplets
]
train_loss = losses.MultipleNegativesRankingLoss(model=model)
Same data, different loss function, dramatically different outcome.
Scaling Up on NVIDIA DGX Spark
The local proof-of-concept with all-MiniLM-L6-v2 (22M parameters) showed the approach works. But would a larger model benefit more from domain-specific fine-tuning?
We ran a three-model comparison on an NVIDIA DGX Spark (GB10), an ARM64 system with 130.7 GB of unified CPU/GPU memory:
Results
| Model | Params | Feature Gap (base → tuned) | Acc@1 (base → tuned) |
|---|---|---|---|
| all-MiniLM-L6-v2 | 22M | 0.21 → 0.41 | 91.5% → 97.4% |
| bge-large-en-v1.5 | 335M | 0.10 → 0.49 | 90.0% → 98.7% |
| bge-m3 | 568M | 0.13 → (OOM) | 92.8% → — |
The "feature gap" measures the difference in average cosine similarity between same-feature NOTAM pairs and different-feature pairs. Higher means better discrimination.
The surprising finding: bge-large started with the worst feature gap (0.10) but ended with the best (0.49). Larger models have more capacity to absorb domain-specific semantics, but their general-purpose pre-training actually makes them less suited to aviation text out of the box — they embed NOTAMs too close together because the text all looks structurally similar. Fine-tuning flips the ranking completely.
Worth noting: MiniLM at 22M parameters hit 97.4% accuracy — within 1.3 points of the much larger bge-large. For latency-sensitive or edge deployment scenarios, that's a very practical option at a fraction of the compute cost.
What Better Embeddings Actually Look Like
Numbers tell one story. Retrieval results tell a better one.
Query: "VOR navigation aid unserviceable"
| Rank | MiniLM (baseline) | bge-large (fine-tuned) |
|---|---|---|
| 1 | Teesside CTA/CTR/ATZ description (0.65) | Mikonos VOR/DME MKN 110 MHz U/S (0.15) |
| 2 | ILS approach localiser calibration (0.66) | MVY VOR/DME U/S (0.17) |
| 3 | Airspace reservation activated (0.67) | VOR LMB 111.800MHz U/S (0.18) |
MiniLM returned three unrelated results — not a single VOR outage. The fine-tuned model returned three actual VOR NOTAMs from different airports, all correctly matching the query intent.
Query: "crane near airport obstacle"
| Rank | MiniLM (baseline) | bge-large (fine-tuned) |
|---|---|---|
| 1 | Mobile crane erected at LICT (0.40) | Tempo crane at LSGG (0.11) |
| 2 | Mobile crane at EKEB (0.46) | Tempo crane at LSGG (0.11) |
| 3 | Mobile crane at CYNJ (0.46) | Crane erected at EHRD (0.11) |
Both found crane NOTAMs, but the fine-tuned model's distances are dramatically tighter (0.11 vs 0.40–0.46), indicating far higher confidence in the matches and enabling reliable distance-based filtering.
Across all test queries, the fine-tuned model consistently produced lower distances (0.10–0.24 vs 0.40–0.67), better domain discrimination, and zero overlap with the baseline's top-3 results.
Key Takeaways
Domain labels you already have are training data. ICAO Q-codes gave us 15,000+ labelled training pairs with zero manual annotation. Before reaching for LLM-generated labels or expensive human annotation, look for existing classification schemes in your data.
Loss function choice can make or break fine-tuning. TripletLoss destroyed our model; MultipleNegativesRankingLoss with the exact same data produced excellent results. MNRL's in-batch negatives provide stronger and more stable gradients.
Larger models benefit more from domain fine-tuning. bge-large went from worst-performing to best-performing after fine-tuning. If you're going to invest in fine-tuning, use a model with enough capacity to learn your domain.
Hard negatives are essential. Same-airport-different-feature negatives force the model to learn real semantic distinctions rather than superficial lexical similarity.
Embedding distance calibration matters for RAG. The fine-tuned model's tighter distance distribution enables reliable retrieval thresholds — critical for safety applications where returning irrelevant results isn't just unhelpful, it's potentially dangerous.
Fine-tuned on ~15K aviation triplets. 3 epochs. 70 minutes on a DGX Spark. 98.7% nearest-neighbour accuracy. Sometimes the best training data is the metadata you already have.
This work is part of Airside Labs' ongoing research into AI safety and compliance for aviation systems. If you're building AI-powered tools for aviation and care about retrieval quality, get in touch.

Alex Brooker
Founder & CEO, Airside Labs
Alex Brooker brings over 25 years of experience in aviation, defense, and safety-critical systems. Former VP of R&D at Cirium (RELX PLC) and Principal Engineer at BAE Systems. Award winner (IHC Janes Innovation 2016, Technology 2015). Alex founded Airside Labs to ensure AI systems truly understand their domains through rigorous evaluation and testing.
Connect on LinkedInReady to enhance your AI testing?
Contact us to learn how AirsideLabs can help ensure your AI systems are reliable, compliant, and ready for production.
Book A Demo